
机器翻译最新进展如何(人工智能科普|机器翻译究竟是什么?)

长篇外文看不懂?Google帮你全篇一键翻译。
出国旅游语言不通?翻译机随身带,沟通无障碍!

无论是在网页、APP还是其它带有翻译功能的软硬件,都用到了一项重要的人工智能技术——机器翻译。
今天就来为大家介绍一下机器翻译的基本知识点。干货满满,不要错过哦!
机器翻译的一般流程
机器翻译其实是利用计算机把一种自然语言翻译成另一种自然语言的过程,基本流程大概分为三块:预处理、核心翻译、后处理。
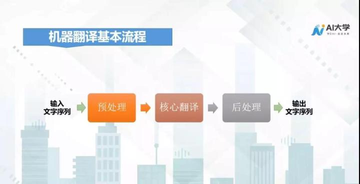
预处理是对语言文字进行规整,把过长的句子通过标点符号分成几个短句子,过滤一些语气词和与意思无关的文字,将一些数字和表达不规范的地方,归整成符合规范的句子。
核心翻译模块是将输入的字符单元、序列翻译成目标语言序列的过程,这资源之家】每日免费更新最热门的副业项目资源是机器翻译中最关键最核心的地方。
后处理模块是将翻译结果进行大小写的转化、建模单元进行拼接,特殊符号进行处理,使得翻译结果更加符合人们的阅读习惯。
机器翻译的技术原理
在讲机器翻译的技术原理之前,我们先来看一张机器翻译技术发展历史图:
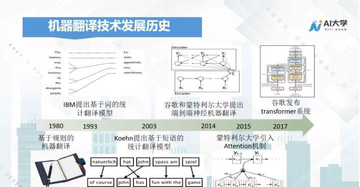
20世纪80年代基于规则的机器翻译开始走向应用,这是第一代机器翻译技术。随着机器翻译的应用领域越来越复杂,基于规则的机器翻译的局限性开始显现,应用场景越多,需要的规则也越来越多,规则之间的冲突也逐渐出现。
于是很多科研学家开始思考,是否能让机器自动从数据库里学习相应的规则,1993年IBM提出基于词的统计翻译模型标志着第二代机器翻译技术的兴起。
2014年谷歌和蒙特利尔大学资源之家】每日免费更新最热门的副业项目资源提出的第三代机器翻译技术,也就是基于端到端的神经机器翻译,标志着第三代机器翻译技术的到来。
看完了机器翻译技术的迭代发展,我们来了解下三代机器翻译的核心技术:规则机器翻译、统计机器翻译、神经机器翻译。
规则机器翻译
基于规则的机器翻译大概有三种技术路线,第一种是直接翻译的方法,对源语言做完分词之后,将源语言的每个词翻译成目标语言的相关词语,然后拼接起来得出翻译结果。
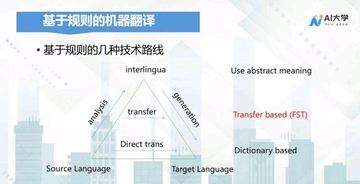
由于源语言和目标语言并不在同一体系下,句法顺序有很大程度上的出入,直接拼接起来的翻译结果,效果往往并不理想。
于是科研人员提出了第二个规则机器翻译的方法,引用语言学的相关知识,对源语言的句子进行句法的分析,由于应用了相关句法语言学的知识,因资源之家】每日免费更新最热门的副业项目资源此构建出来的目标译文是比较准确的。
但这里依然存在着另外一个问题,只有当语言的规则性比较强,机器能够做法分析的时候,这套方法才比较有效。
因此在此基础之上,还有科研人员提出,能否借助于人的大脑翻译来实现基于规则的机器翻译?
这里面涉及到中间语言,首先将源语言用中间语言进行描述,然后借助于中间语言翻译成我们的目标语言。
但由于语言的复杂性,其实很难借助于一个中间语言来实现源语言和目标语言的精确描述。
讲完了基于规则的机器翻译的三种技术路线,我们用一张图来总结下它的优缺点:

统计机器翻译
机器翻译的第二代技术路线,是基于统计的机器翻译,其核心在于设计概率模型对翻译过程建模。
比如我们用x来表示原句子,用y来表示目资源之家】每日免费更新最热门的副业项目资源标语言的句子,任务就是找到一个翻译模型
θ 。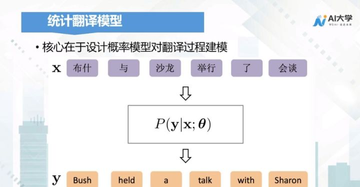
最早应用于统计翻译的模型是信源信道模型,在这个模型下假设我们看到的源语言文本 x是由一段目标语言文本 y 经过某种奇怪的编码得到的,那么翻译的目标就是要将 y 还原成 x,这也就是一个解码的过程。
所以我们的翻译目标函数可以设计成最大化Pr( │ ),通过贝叶斯公式,我们可以把Pr( │ )分成两项,Pr( ) 的语言模型,Pr( | )的翻译模型

如果将这个目标函数两边同取log,我们就可以得到对数线性模型,这也是我们在工程中实际采用的模型。
对数线性模型不仅包括了翻译模型、语言模型,还包括了调序模型,扭曲模型和词数惩罚模型,通过这些模型共同约束来实现资源之家】每日免费更新最热门的副业项目资源源语言到目标语言的翻译。
讲完了统计机器翻译的相关知识,我们来看下基于短语的统计翻译模型的三个基本步骤:
1、源短语切分:把源语言句子切分成若干短语
2、源短语翻译:翻译每一个源短语
3、目标短语调序:按某顺序把目标短语组合成句子
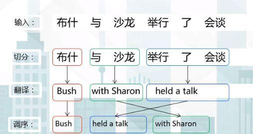
最后,我们依旧用一张图来总结下基于统计机器翻译的优缺点:

神经机器翻译
讲完了基于规则的机器翻译和基于统计的机器翻译,接下来我们来看下基于端到端的神经机器翻译。
神经机器翻译基本的建模框架是端到端序列生成模型,是将输入序列变换到输出序列的一种框架和方法。
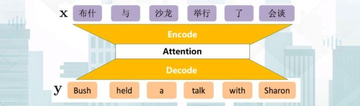
其核心部分有两点,一是如何表征输入序列(编码),二是如何获得输出序列(解码)。
对于机器翻译而言不仅包括了编码和解码两个部分,还引入资源之家】每日免费更新最热门的副业项目资源了额外的机制——注意力机制,来帮助我们进行调序。
下面我们用一张示意图来看一下,基于RNN的神经机器翻译的流程:
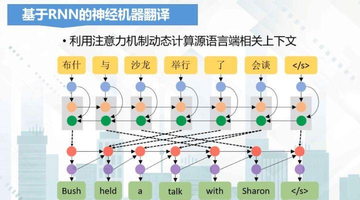
首先我们通过分词得到输入源语言词序列,接下来每个词都用一个词向量进行表示,得到相应的词向量序列,然后用前向的RNN神经网络得到它的正向编码表示。
再用一个反向的RNN,得到它的反向编码表示,最后将正向和反向的编码表示进行拼接,然后用注意力机制来预测哪个时刻需要翻译哪个词,通过不断地预测和翻译,就可以得到目标语言的译文。
